前言
公司开发需求,需要使用 ESP32开发板 开发某个项目,使用 micropython 语言开发。以下记录开发过程中遇到的关于屏幕显示中文的一些问题的解决方案。
准备
- 硬件
- ESP32 开发板
- 微雪 1.54inch e-Paper Module (C) 墨水屏
- 软件
引用相关资料
实现过程
思考,原理与前提
想要在一块显示器上显示东西,其实就是操作显示器的像素点,让对应的像素点显示对应的颜色即可。由于这里使用的是墨水屏以及需求上不需要彩色显示,只需要考虑黑底白字或者白底黑字的显示效果即可。
首先需要在ESP32开发板中刷入Micropython固件,以及需要一个墨水屏的驱动来控制像素点。
在满足以上条件后,测试下驱动是否可用就可以进行下一步的过程了。
关于IDE
最开始使用的是 Thonny 来做开发,可以直接修改板载文件与执行,能直观的看到板载的文件,但由于编辑器的代码提示等一系列的编辑功能实在是过于羸弱,改为用 VSCode 加插件的形式开发。
VSCode 使用 RT-Thread MicroPython 插件与主板进行连接,虽然有 设备文件列表 这个功能,但这里使用同步功能时一直失败,故保留 Thonny 当作文件管理器使用。
操作墨水屏
原生API显示
最初,本着先找找看有没有可用的库的心思,在翻阅 micropython 文档的时候找到了 FrameBuffer 这个类。这个类可以在显示器上绘制各种基本形状,图像,文本。FrameBuffer 自带 FrameBuffer.text(s, x, y[, c]) 方法,可以直接在显示器上绘制文字,但缺点是这个方法只能绘制8x8像素的英文文本,不支持中文以及字体修改,不能满足我们的需求。
简单编写一个案例测试下:
from machine import SoftSPI, Pin
from e154 import EPD
# 初始化
epaper = SoftSPI(baudrate=40000000,sck=Pin([*]), mosi=Pin([*]), miso=Pin([*]))
display = EPD(epaper,[*],[*],[*],[*])
display.text("text", 10, 10)
display.show()
其中 e154 是一个基于 FrameBuffer 的墨水屏驱动。
显示效果为如下

文本取模显示
继续查找实现方案,在 引.1 中找到了三种解决方案,首先是传统的文本取模做法: 原理是使用取模软件将所需字体文字转换为字体点阵数据,以硬编码的方式存放在代码中,在需要的时候直接调用如 FrameBuffer.pixel(x, y[, c]) 之类的操作显示器像素的方法来进行绘制。
首先我们打开 PCtoLCD2002 软件,点击左上角的模式切换为字符模式
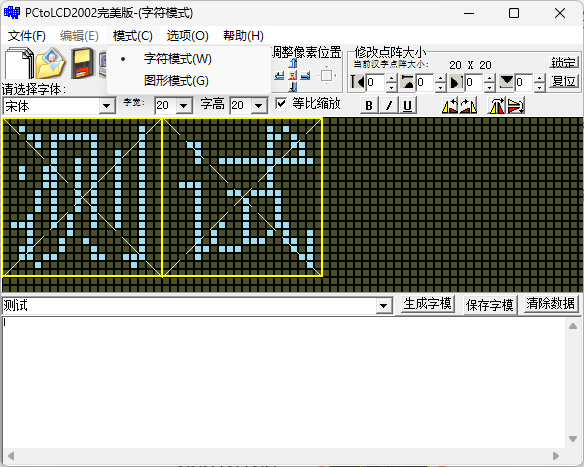
然后点击齿轮按钮按照下图更改字模选项。
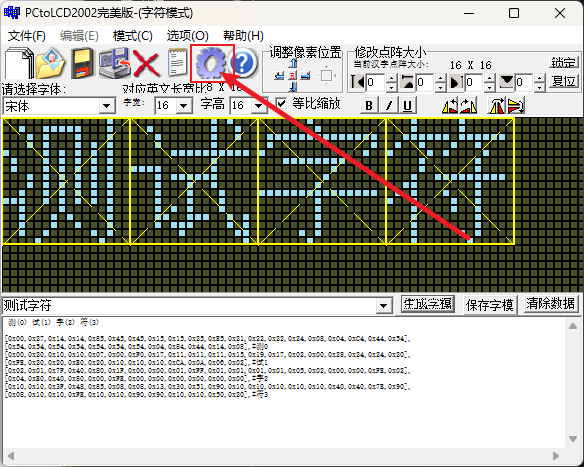
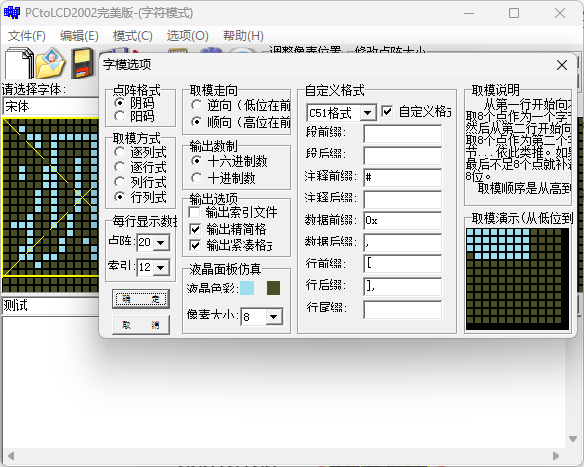
点击确定后自动跳到主页,点击生成字模按钮
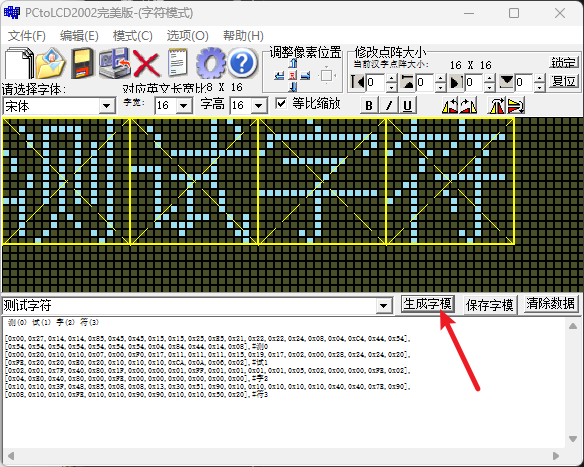
下面输出框的这一长串就是我们需要的字模了,简单解释下这个字模的数据是什么吧。
(以下大部分为 引.1 的内容)
我们使用了行列式,顺向,十六进制的方式,在右下角展示了取模的过程,其取模是这样描述的:
从第一行开始向右取8个点作为一个字节,然后从第二行开始向右取8个点作为第二个字节…依此类推。如果最后不足8个点就补满8位。 取模顺序是从高到低,即第一个点作为最高位。如*——-取为10000000
也就是说从左上角开始,从左到右每8个点为一份数据(一个字节),然后往下到底为第一列,再从第二行右侧读第二列,如果后面的不够8个点,就往后补零补满8个点。
以字符 V 来做示例:
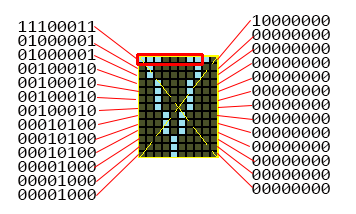
把其中的显示的像素作为 1,不显示的像素作为 0,按图中从上到下有两列的二进制数据,然后全部连到一块,如下:
[11100011, 01000001, 01000001, 00100010, 00100010, 00100010, 00100010, 00010100, 00010100, 00010100, 00001000, 00001000, 00001000, 10000000, 00000000, 00000000, 00000000, 00000000, 00000000, 00000000, 00000000, 00000000, 00000000, 00000000, 00000000, 00000000]
把它们全部转换为十进制为:
[227,65,65,34,34,34,34,20,20,20,8,8,8,128,0,0,0,0,0,0,0,0,0,0,0,0]
如果转为十六进制,前缀 0x 就是:
[0xE3,0x41,0x41,0x22,0x22,0x22,0x22,0x14,0x14,0x14,0x08,0x08,0x08,0x80,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00]
这就是点阵字库的代码了,绘制时只要要按原样读取出二进制数据,就能得知每个点的开关状态,将这些开关状态绘制到屏幕相应位置的像素点上,就能完整的绘制出整个文字了。
使用以下代码进行绘制,注意这里首先要知道字符的高度,因为是从上到下读,每个单位代表 8 个点的数据,而每相同于字体高度的数据相当于一列
from machine import SoftSPI, Pin
from e154 import EPD
# 初始化
epaper = SoftSPI(baudrate=40000000,sck=Pin([*]), mosi=Pin([*]), miso=Pin([*]))
display = EPD(epaper,[*],[*],[*],[*])
# 生成的字模高度
font_height =20
bits = ([0x00,0x20,0x1B,0x0A,0x02,0x02,0x26,0x26,0x06,0x0A,0x0A,0x0A,0x12,0x72,0x10,0x11,0x31,0x36,0x08,0x00],
[0x00,0x00,0xF0,0x10,0x12,0x52,0x52,0x52,0x52,0x52,0x52,0x52,0x92,0x92,0x80,0x20,0x10,0x19,0x00,0x00],
[0x00,0x40,0x40,0x40,0x40,0x40,0x40,0x40,0x40,0x40,0x40,0x40,0x40,0x40,0x40,0x40,0x40,0xC0,0x80,0x00],#测0
[0x00,0x00,0x00,0x18,0x08,0x09,0x00,0x00,0x38,0x08,0x08,0x08,0x08,0x09,0x0A,0x0A,0x0D,0x08,0x00,0x00],
[0x00,0x05,0x06,0x04,0x04,0xFF,0x04,0x04,0x04,0xDE,0x22,0x22,0x22,0x23,0x25,0x39,0xC0,0x00,0x00,0x00],
[0x00,0x00,0x80,0xC0,0x40,0xE0,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x20,0xA0,0xA0,0x60,0x20,0x00],#试1
[0x00,0x00,0x00,0x00,0x1F,0x10,0x30,0x07,0x00,0x00,0x00,0x3F,0x00,0x00,0x00,0x00,0x00,0x01,0x00,0x00],
[0x00,0x80,0x60,0x20,0xFF,0x00,0x01,0xFE,0x0C,0x10,0x60,0xFF,0x20,0x20,0x20,0x20,0x20,0xE0,0x40,0x00],
[0x00,0x00,0x00,0x00,0xC0,0x80,0x00,0x00,0x00,0x00,0x40,0xE0,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00],#字2
[0x00,0x04,0x0C,0x0E,0x11,0x21,0x43,0x02,0x04,0x0C,0x0C,0x14,0x24,0x04,0x04,0x04,0x04,0x04,0x08,0x00],
[0x00,0x04,0x08,0xEE,0x11,0x21,0x21,0x02,0x02,0xFF,0x02,0x42,0x22,0x22,0x22,0x02,0x02,0x1E,0x06,0x00],
[0x00,0x00,0x00,0xC0,0x00,0x00,0x00,0x00,0x00,0xE0,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00]#符3
)
# Y轴初始化偏移量
y_axis = 10
# X轴初始化偏移量
x_axis = 10
# 色彩 1为白色
color = 1
# 列数
cols = len(bits)
# 逐行绘制
for y in range(font_height):
top = y_axis + y
# 列行式,顺向读取方式
for col in range(cols):
b = bits[col][y]
for x in range(8):
# 从左读取位判断是否为1
if b << x & 0x80:
display.pixel(x_axis + x + col * 8, top, color)
# 在完成所有像素设置后,可能需要调用刷新方法将显示内容更新到屏幕上
display.show()
生成的效果大概是这样。

生成自定义字库文件
在 引.1 还提到了一种使用 MicroPython 自带的 Btree 来保存数据的方案,其降低了字节码的转换过程和内存的占用,但还是有一些麻烦:
-
btree 库只在 MicroPython 固件中,每次生成 btree 字库要先用字模生成代码,再将代码放进 MicroPython 代码中上传到开发板来执行生成字库,太麻烦。
-
开发板性能很弱,btree 虽然读取高效,但是因为实现相对简单,写入并不高效,因为内部要对索引进行分页,排序等处理,所以字符一旦多起来,生成字库的速度就会呈指数级下降,在我后面做另一个项目时,因为要写入两千个字符,等的时间非常长,而且因为内存原因总是失败。
-
btree 虽然读取的非常快,但因为其是可改动的,并且内部使用页的方式去维护数据,所以难免会存在空闲的区间,MicroPython 并没有提供太多的配置和方法去调整这一块的参数(只有 pagesize),所以 btree 仍然会使用不少的额外空间,要知道开发板的存储空间也很宝贵。
由于开发时间的限制,我们直接跳下一种方案,使用自定义字库格式。
(以下有大段为 引.1 内容)
自定义字库要达到以下几点需求:
-
生成字库要简单,尤其是生成大量字符的字库时不要那么麻烦。
-
字库要能直接在电脑上生成,不要依赖于固件内部的功能,要能把电脑上生成好的字库文件直接传到开发板中就能使用。
-
字库的读取性能要高效,得像 btree 一样那么高效,不能动不动就来一个全文件的扫描。
-
字库文件要精简,不要有任何额外的冗余的空间占用,最好每一个字节都拿来用。
首先是文件的格式,文件内部分为三个区域,分别是信息区(存储字体名,字体宽高等描述数据),索引区(用于查找字符位置的索引区,使用二分法查找,按顺序排列的定长字符),字符点阵数据区(与索引一样顺序的点阵数据区)。
这里要求每个字库下的字符都是定长的,比如都是 utf-8 占三个字节长度,普通英文 ASCII 占一个字节长度,只有单个字符定长了才能方便进行二分法查找。
字库包含的字符长度不一定,所以索引、数据区的长度也不一定。
因为上面的原因我需要在字体区信息区里存储至少字体宽、高、单个字符在索引中的长度、以及整个索引或数据区的长度或开始位置,然后再加上一个字体的名称,最终格式如下:
| 20个字节字符串为字体的名称 | 1字节 unsigned char 为字体宽 | 1字节 unsigned char 为字体高 | 2 字节 unsigned short 为包含的字符数量 | 4 字节 unsigned int 为点阵数据开始位置 |
| 紧跟着所有相同长度(1字节每个英文或3字节每个UTF-8中文)的从低到高排序字符作为二分查找索引 | 从点阵数据开始位置紧跟着所有点阵数据,顺序与索引相同 |
索引长度 = 点阵开始位置减去索引开始位置28
每个字符在索引中占用长度 = 索引长度 / 字符数量
每个字符占用的点阵数据长度 = 向上取整(字符宽 / 8) * 字符高 (这是由取模软件决定的,取模方式:阴码,行列式,顺向)
这样头部28字节就是信息区,往后到点阵数据开始位置为索引区,索引区后面紧跟的就是点阵数据区,没有一点浪费。
读取是先从信息区取到索引结束位置,然后根据索引长度/字符数得到每个字符的字节数,然后在索引区使用二分法快速查找到指定字符所在的位置,再位移到对应的点阵数据区位置取出点阵数据交给绘制的代码即可。
生成的过程也很简单,我写了一段脚本将已经排重的字符进行排序保存成文本文件,使用 PCtoLCD2002 软件的导入大量文本文件直接生成索引和二进制字库文件(点击打开文本文件导入文件,勾选生成索引文件和生成二进制字库文件,再点击开始生成即可),将这两个文件拷贝到脚本所在目录中执行另一个脚本即可直接生成目标字体文件。
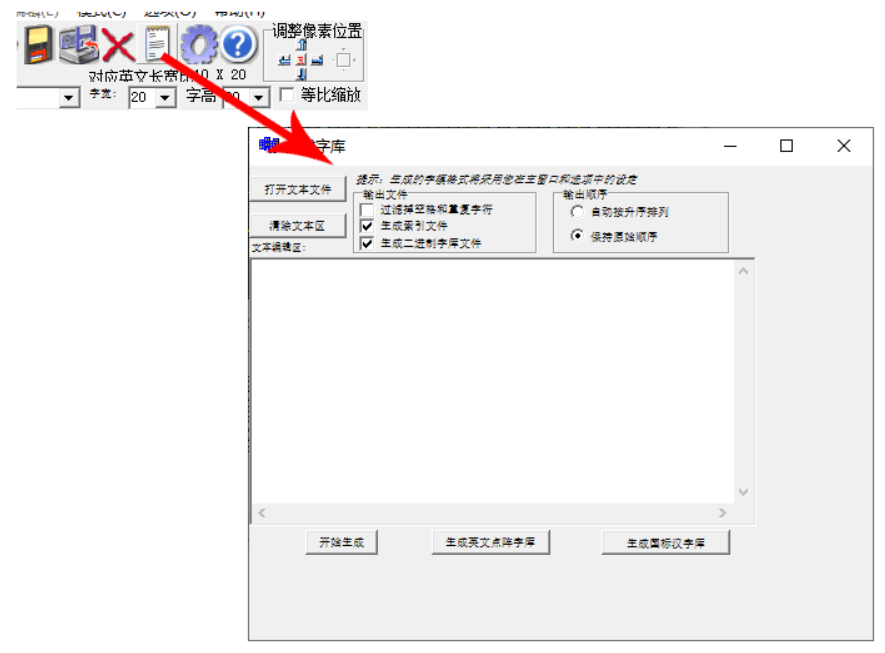
对文本进行排序的脚本,会生成 text-index.txt 文件:
GenTextIndex.py
'''
将字符串排序后保存为 GBK 文件
用于给 PCtoLCD2000 软件生成字模,排序主要用于生成字体文件后用二分法查找
'''
# 这里存放的是要进行排序的文字,注意文字要先排重
text = '''
测试字符
'''
text = text.replace('\n', '')
text_arr = []
for word in text:
text_arr.append(word)
text_arr.sort()
text = ''.join(text_arr)
# 保存成 GBK 后用字模软件打开
f = open('text-index.txt', 'wt', encoding='gbk')
f.write(text)
f.close()
print(text)
生成字体的文件,会在 fonts 目录下生成 .font 文件:
GenFont.py
import struct
'''
将字体取模软件生成的字体与索引生成专用的点阵字体文件
'''
font_name = 'TestFont'
font_width = 20
font_height = 20
file_name = '1' # 字体与索引文件名的前缀,后面跟的分别是 .fon 和 _index.txt
f = open('fonts/%s.font' % font_name, 'wb')
# 读出索引,并从 GBK 转为 UTF-8
fi = open('%s_index.TXT' % file_name, 'r', encoding='gbk')
text = fi.read()
fi.close()
text_bin = text.strip().encode('utf-8')
count = len(text_bin.decode())
# 打开字体文件
fon = open('%s.fon' % file_name, 'rb')
# blen = font_width + font_height
# 前 20 为字体名
f.write(font_name.encode())
f.seek(20)
# 20:21 字体宽,21:22 字体高,22:24 字体数量,24:28 字体点阵数据开始位置
font_pos = len(text_bin) + 28
f.write(struct.pack('BBHI', font_width, font_height, count, font_pos))
f.write(text_bin)
# 写入字体点阵数据
fi = open('%s.FON' % file_name, 'rb')
f.write(fi.read())
fi.close()
f.close()
文件结构:
调用自定义字库文件并在显示器上显示
将 .font 文件传输到设备上,使用以下代码进行读取测试:
import struct
import math
from machine import SoftSPI, Pin, SPI
from e154 import EPD
FF_INDEX_START = 28
class FileFont():
'''
基于文件的字体文件格式
此字体格式为最紧凑的格式,文件定义如下:
| 20个字节字符串为字体的名称 | 1字节 unsigned char 为字体宽 | 1字节 unsigned char 为字体高 | 2 字节 unsigned short 为包含的字符数量 | 4 字节 unsigned int 为点阵数据开始位置 |
| 紧跟着所有相同长度(1字节每个英文或3字节每个UTF-8中文)的从低到高排序字符作为二分查找索引 | 从点阵数据开始位置紧跟着所有点阵数据,顺序与索引相同 |
索引长度 = 点阵开始位置减去索引开始位置28
每个字符在索引中占用长度 = 索引长度 / 字符数量
每个字符占用的点阵数据长度 = 向上取整(字符宽 / 8) * 字符高 (这是由取模软件决定的,取模方式:阴码,行列式,顺向)
'''
def __init__(self, name):
self.fp = open('fonts/%s.font' % name, 'rb')
self.name = self.fp.read(20).decode()
# 字体宽,高,数量,点阵数据开始位置
w, h, self.count, self.data_pos = struct.unpack('BBHI', self.fp.read(8))
# 一个字符在索引中占用的长度
self.char_len = int((self.data_pos - FF_INDEX_START) / self.count)
# 一个字符的点阵数据占用的长度
self.bits_len = math.ceil(w / 8) * h
self.height = h
self.width = w
print(h)
print(w)
# super().__init__(w, h)
def get_bits(self, char):
'''
读取指定字符的点阵数据
'''
# 二分法查找字符的索引位置
first = 0
last = self.count
pos = None
while first <= last:
middle = (first + last) // 2
self.fp.seek(FF_INDEX_START + middle * self.char_len)
item = self.fp.read(self.char_len).decode()
if char == item:
pos = middle
break
elif char < item:
last = middle - 1
else:
first = middle + 1
if pos is None:
return None
# 读取点阵数据
self.fp.seek(self.data_pos + pos * self.bits_len)
return self.fp.read(self.bits_len)
# 创建图像缓冲区
width = 200
height = 200
epaper = SoftSPI(baudrate=40000000,sck=Pin([*]), mosi=Pin([*]), miso=Pin([*]))
display = EPD(epaper,[*],[*],[*],[*])
# # 清空图像缓冲区
display.fill(1) # 0表示黑色背景,清空图像缓冲区
# 使用 FileFont 类读取 "example.font" 字体文件
font = FileFont("TestFont")
# 绘制文本
text = '\u6587\u672C' # 测试文字
x_axis = 20
y_axis = 20
color = 0 # 1表示白色文本
# 遍历文本的每个字符
for char in text:
# 获取当前字符的点阵数据
bits = font.get_bits(char)
# 使用切片操作将数组切成三份
part1 = bits[:20] # 获取前三个元素
part2 = bits[20:40] # 获取中间三个元素
part3 = bits[40:60] # 获取最后三个元素
# 将切片后的三份存储在一个变量里(可以使用列表或元组)
bitlist = [part1, part2, part3]
print(bitlist)
# 逐行绘制
for y in range(font.height):
top = y_axis + y
# 列行式,顺向读取方式。每一列后方跟的是下一列,所以 (行 + 列 * 字体高) 就代表所以行的下一列。
for col in range(len(bitlist)):
b = bitlist[col][y]
for x in range(8):
# 从左读取位判断是否为1
if b << x & 0x80:
display.pixel(x_axis + x + col * 8, top, color)
# 移动到下一个字符的位置
x_axis += font.width
# 在完成所有像素设置后,可能需要调用刷新方法将显示内容更新到屏幕上
display.show()
最终效果如下:

绘制文本的入参必须是 unicode 字符,这里使用 BE工具(BeryEnigma) 来进行 unicode 编码。
后续还可修改绘制代码来实现居中,换行等功能。以下展示如何居中显示:
# 计算文本宽度和高度
text_width = font.width * len(message)
text_height = font.height
# 计算水平方向上的起始位置,使文本居中
x_start = (display.width - text_width) // 2
# 计算垂直方向上的起始位置,使文本居中
y_start = (display.height - text_height) // 2
# 遍历文本的每个字符
for char in message:
# 获取当前字符的点阵数据
bits = font.get_bits(char)
part1 = bits[:20]
part2 = bits[20:40]
part3 = bits[40:60]
bitlist = [part1, part2, part3]
for y in range(font.height):
top = y_start + y # 使用计算得到的垂直方向起始位置
x_pos = x_start # 使用计算得到的水平方向起始位置
for col in range(len(bitlist)):
b = bitlist[col][y]
for x in range(8):
if b << x & 0x80:
display.pixel(x_pos + x + col * 8, top, color)
x_pos += font.width # 移动到下一个字符的位置
# y_start += font.height # 更新下一个字符的垂直方向起始位置
x_start += font.width # 更新下一个字符的水平方向起始位置

最后附上使用的驱动代码,代码来自网络,有些许修改
from micropython import const
from time import sleep_ms
import ustruct
from machine import Pin
import framebuf
# Display resolution
EPD_WIDTH = const(200)
EPD_HEIGHT = const(200)
# Display commands
DRIVER_OUTPUT_CONTROL = const(0x01)
BOOSTER_SOFT_START_CONTROL = const(0x0C)
#GATE_SCAN_START_POSITION = const(0x0F)
DEEP_SLEEP_MODE = const(0x10)
DATA_ENTRY_MODE_SETTING = const(0x11)
#SW_RESET = const(0x12)
#TEMPERATURE_SENSOR_CONTROL = const(0x1A)
MASTER_ACTIVATION = const(0x20)
#DISPLAY_UPDATE_CONTROL_1 = const(0x21)
DISPLAY_UPDATE_CONTROL_2 = const(0x22)
WRITE_RAM = const(0x24)
WRITE_VCOM_REGISTER = const(0x2C)
WRITE_LUT_REGISTER = const(0x32)
SET_DUMMY_LINE_PERIOD = const(0x3A)
SET_GATE_TIME = const(0x3B) # not in datasheet
#BORDER_WAVEFORM_CONTROL = const(0x3C)
SET_RAM_X_ADDRESS_START_END_POSITION = const(0x44)
SET_RAM_Y_ADDRESS_START_END_POSITION = const(0x45)
SET_RAM_X_ADDRESS_COUNTER = const(0x4E)
SET_RAM_Y_ADDRESS_COUNTER = const(0x4F)
TERMINATE_FRAME_READ_WRITE = const(0xFF) # aka NOOP
class EPD(framebuf.FrameBuffer):
LUT_FULL_UPDATE = bytearray(b'\x02\x02\x01\x11\x12\x12\x22\x22\x66\x69\x69\x59\x58\x99\x99\x88\x00\x00\x00\x00\xF8\xB4\x13\x51\x35\x51\x51\x19\x01\x00')
LUT_PARTIAL_UPDATE = bytearray(b'\x10\x18\x18\x08\x18\x18\x08\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x00\x13\x14\x44\x12\x00\x00\x00\x00\x00\x00')
def __init__(self, spi, cs, dc, rst, busy):
self.spi = spi
self.cs = Pin(cs,Pin.OUT,value = 1)
self.dc = Pin(dc,Pin.OUT,value = 0)
self.rst = Pin(rst,Pin.OUT,value = 0)
self.busy = Pin(busy,Pin.IN)
self.width = EPD_WIDTH
self.height = EPD_HEIGHT
self.pages = self.height//8
self.buffer = bytearray(self.width*self.pages)
super().__init__(self.buffer, self.width, self.height,
framebuf.MONO_HLSB)
self.init()
def clear(self):
self.buffer = bytearray(self.width*self.pages)
def show(self):
self.set_frame_memory(self.buffer,0,0,200,200)
self.display_frame()
def _command(self, command, data=None):
self.dc.value(0)
self.cs.value(0)
self.spi.write(command.to_bytes(1,'big'))
#self.spi.write(bytearray([command]))
self.cs.value(1)
if data is not None:
self._data(data)
def _data(self, data):
self.dc.value(1)
self.cs.value(0)
self.spi.write(data)
self.cs.value(1)
def init(self,isPART = True):
self.reset()
self._command(DRIVER_OUTPUT_CONTROL)
self._data(bytearray([(EPD_HEIGHT - 1) & 0xFF]))
self._data(bytearray([((EPD_HEIGHT - 1) >> 8) & 0xFF]))
self._data(bytearray([0x00])) # GD = 0 SM = 0 TB = 0
self._command(BOOSTER_SOFT_START_CONTROL, b'\xD7\xD6\x9D')
self._command(WRITE_VCOM_REGISTER, b'\xA8') # VCOM 7C
self._command(SET_DUMMY_LINE_PERIOD, b'\x1A') # 4 dummy lines per gate
self._command(SET_GATE_TIME, b'\x08') # 2us per line
self._command(DATA_ENTRY_MODE_SETTING, b'\x03') # X increment Y increment
#self._command(DATA_ENTRY_MODE_SETTING, b'\x07') # X increment Y increment
if isPART:
self.set_lut(self.LUT_FULL_UPDATE)
else:
self.set_lut(self.LUT_PARTIAL_UPDATE)
def wait_until_idle(self):
while self.busy.value() == 1:
sleep_ms(100)
def reset(self):
self.rst.value(0)
sleep_ms(200)
self.rst.value(1)
sleep_ms(200)
def set_lut(self, lut):
self._command(WRITE_LUT_REGISTER, lut)
# put an image in the frame memory
def set_frame_memory(self, image, x, y, w, h):
# x point must be the multiple of 8 or the last 3 bits will be ignored
x = x & 0xF8
w = w & 0xF8
if (x + w >= self.width):
x_end = self.width - 1
else:
x_end = x + w - 1
if (y + h >= self.height):
y_end = self.height - 1
else:
y_end = y + h - 1
self.set_memory_area(x, y, x_end, y_end)
self.set_memory_pointer(x, y)
self._command(WRITE_RAM, image)
# replace the frame memory with the specified color
def clear_frame_memory(self, color):
self.set_memory_area(0, 0, self.width - 1, self.height - 1)
self.set_memory_pointer(0, 0)
self._command(WRITE_RAM)
# send the color data
for i in range(0, self.width // 8 * self.height):
#self._data(bytearray([color]))
self._data(bytearray(color))
# draw the current frame memory and switch to the next memory area
def display_frame(self):
# self._command(DISPLAY_UPDATE_CONTROL_2, b'\xC4')
# self._command(MASTER_ACTIVATION)
# self._command(TERMINATE_FRAME_READ_WRITE)
self._command(DISPLAY_UPDATE_CONTROL_2, b'\xf7')
self._command(MASTER_ACTIVATION)
self.wait_until_idle()
# specify the memory area for data R/W
def set_memory_area(self, x_start, y_start, x_end, y_end):
self._command(SET_RAM_X_ADDRESS_START_END_POSITION)
# x point must be the multiple of 8 or the last 3 bits will be ignored
self._data(bytearray([(x_start >> 3) & 0xFF]))
self._data(bytearray([(x_end >> 3) & 0xFF]))
self._command(SET_RAM_Y_ADDRESS_START_END_POSITION, ustruct.pack("<HH", y_start, y_end))
# specify the start point for data R/W
def set_memory_pointer(self, x, y):
self._command(SET_RAM_X_ADDRESS_COUNTER)
# x point must be the multiple of 8 or the last 3 bits will be ignored
self._data(bytearray([(x >> 3) & 0xFF]))
self._command(SET_RAM_Y_ADDRESS_COUNTER, ustruct.pack("<H", y))
self.wait_until_idle()
# to wake call reset() or init()
def sleep(self):
self._command(DEEP_SLEEP_MODE, b'\x01') # enter deep sleep A0=1, A0=0 power on
#self.wait_until_idle()